/*****************************************************************************
Sparse.cpp -(Parser.cc) -
began: 6/16 created searchout function 6/17
fixed parser function: 6/21- finished / tested 6/25 - 6/26
completed searchOut and auxillary functions 6/26 - 6/27. Tested
and fixed.
6/27 - added all searchable files and made outputted paths be full .html paths.
6/28 - 6/29 Put title parsing features in cheCkfile - performed some debugging
so it would compile - still need to fix logical errors with this.
7/3 - 7/4 Finished debugging checkFile function so that title of the article
could be included in the search. Needed to test for EOL characters
in title so that they are not entered into the array and made sure
title tag test did not extend beyond six characters.
7/6 - Fixed case problems in first character of search term so case is always
irrelevant in search.
8/14 - added preliminary OR search capability to parse function
8/26 - Modified with accompanying files - search (main), locations, and decode
for a more object oriented approach
9/8 - 12 p to 3 p - debugged files with or functionality - merged file back
into one as object oriented approach presented bizarre error messages
that could not be dealt with at this time
9/11 2:30 a - 3:30 a: further deubugged or functionality - never could
determinbe what was causing an absence of output in the test runs -
"all of a sudden it works"- printed source SunWS_cache? folder
9/12 - 9/19 Wasted a lot of time determining the source of the problem to be
the new CC compiler - it does not compile correctly to produce standard
output that works with CGI - use g++ instead.
9/26 - 9/27 Checked to verify how cgi using the sequence from
the reference site outputs buff2 - spaces are
decoded to +s at that point in time. Debugged
parse() function so that it seems to work fully.
Program no longer hangs on execution (changed some
logic expressions - which were doing assignments
inadvertently). Seems to work with quotes. Tosses
ors from expression. Next step make sure truth
tables is being set-up properly - as the correct
number of articles are not being returned - check on
this.
9/29 Fixed call to andOr() happening multiple times by assigning to
varible Fixed ability to call by increasing d (string length to < 5, not 4)
10 / 01 - Fixed first character getting that was causing it to
obtain the next letter of the first word searched for each
successive search term. reversed rows / cols
-OR searching seems to be fixed. AND still has issues
10 / 04
site - ready
Finished primary debugging; beta testing; placed on
for second stage
10/05 More Debugging. Logic errors for phrases beginning with
same letter fixed Could not place on 10/04
Usage: called by the searchform for techNJ, which will pass environment
content variable with the search criteria. Parses this in order
to verify input and generates links to html files with cgi calls
to highlight instances of the search word of that document when the
user clicks upon it.
Output: dynamically generated html code with cgi links to specific html
documents
Errors / Restrictions: If user wishes to search for word and or OR,
these must be placed in quotes - see parse function
Restrictions: Cannot Accept + or & operators for input because these are
part of the cgi encoding sequence. Future revisions might address this
in conjunction with the getting out of the & part of parse if
the last character is a quote
*****************************************************************************/
#include <fstream.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iostream.h>
#include <fstream.h>
#include <ctype.h>
//#define DEBUG//conditional compilation
//for debugging
//Global variables
//Definition of the string data type - taken from examples
const int ucount = 100; //number of URLs search is capable of returning
//(for now)
int atUcount = 0; //counter for URL array
const int strmax = 500; //maximum length of string
const int strmin = 40; //maximum length of a small string
typedef char bigstring[strmax]; //defines a big string as array of 200 chars
typedef char string[strmin]; //defines a small string as array of 10 chars
bigstring search[strmin]; //variable which will store and output search
//search string can hold a maximum of 40
//entries
//this should be enough
int bs = 0;
//variable to increment bigstring counter
//for search variable; needs to be global as
//it will be referenced in the checkfile
//function
int srcTruthTable[strmin] = {
0
};
/*Source and Target (Target declared in function so it is reinitialized each
time through). Truth tables to indicate where and values in search string. If
a word is encountered that is part of an and statement, that location in the
truth table will be set to a 1. When a value is checked, a check will be made
to determine whether the corresponding entry in the truth table and the next
consecutive one are both 1. If they are, an and value has been encountered, and
another word must be searched for in order for the search to return a yes. When
all consecutive ones are matched and the target truth table matches the source
truth table for ones, the search returns a yes.
*/
char firstChar[40]; //array to hold the first characters of the
//search terms
char capFirstChar[40]; //array to hold the first characters
//(capital) of search terms
14 char radissues = "\0"; //variable to store status of radio selection
bigstring URLs[ucount]; //array to hold the urlsc
char titles[100][1000]; //the variable to contain the titles
int numFound = 0; //number of articles found in search
//-------------------------------FILE LOCATIONS---------------------------------
const int numIssues = 7; //the number of issues
const int maxfiles = 20; //the maxiumum # of html files in an issue
short int chk[numIssues]; //the chk variable
string location[numIssues][maxfiles] = {
{
"adamessentials.html",
"learningenglish.html",
"whereinspace.html",
"win96toc.html",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
},
//winter 96 issue - 4
{
"ldclass.html",
"openingnight.html",
"pipandzena.html",
"radsounds.html",
"rosieswalk.html",
"sbwdeluxe.html",
"sprsum96toc.html",
"strategygames.html",
"turtleteasers.html",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0"
},
//spring/summmer96 issue - 9
{
"arnold.html",
"art4metoo.html",
"artland.html",
"bigcalc.html",
"contrib.html",
"editor.html",
"events.html",
"expreshn.html",
"fall96toc.html",
"magictales.html",
"minspeak.html",
"netsites.html",
"njtarpws.html",
"ownvoice.html",
"storytell.html",
"tecktrek.html",
"treasures.html",
"wordsaround.html",
"writeaway.html",
"\0"
},
//fall96 issue - 19
{
"blaster.html",
"blindstud.html",
"blndadlt.html",
"contrib.html",
"editorial.html",
"edspicks.html",
"graph.html",
"graphact.html",
"jespy.html",
"major.html",
"mathkeys.html",
"measure.html",
"monclair.html",
"money.html",
"pwwebspe.html",
"selectin.html",
"snootz.html",
"spr97toc.html",
15 "telltime.html",
"zillions.html"
},
//spring97 issue - 20
{
"bowne.html",
"contrib.html",
"cowriter.html",
"dazzle.html",
"drew.html",
"earle.html",
"editorial.html",
"europe.html",
"inclusion.html",
"index.html",
"mathpad.html",
"pintoo.html",
"premiere.html",
"sensory.html",
"trainingmod.html",
"ultreader.html",
"\0",
"\0",
"\0",
"\0"
},
//winter98 issue - 16
{
"ReforminTeacherEd.html",
"TechInTwo.html",
"AugcommSys.html",
"ProgProfile.html",
"ParentPersp.html",
"resources.html",
"AccessArt.html",
"Reviews.html",
"Editorial.html",
"Contributors.html",
"index.html",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0",
},
//fall98 issue - 11
{
"features.html",
"curriculum.html",
"canWeTalk.html",
"intellitalk.html",
"rev2000.html",
"contribute.html",
"editor.html",
"resources.html",
"jwrite.html",
"sumChart.html",
"curicBox1.html",
"sunburst.html",
"curicBox2.html",
"index.html",
"\0",
"\0",
"\0",
"\0",
"\0",
"\0"
}
};
//2000 issue - 14
//-Finish File Locations
/*****************************************************************************
/*****************************************************************************
**
FUNCTION PROTOTYPES
******************************************************************************
*/
void parse(bigstring);
//function responsible for parsing string once
void searchOut();
//function to generate html links to searches
void checkFile(string, bigstring);
//1st function for below
/****AUXILARRY FUNCTIONS****/
int compareThem(string, string);
//function for comparisons of the search/sample
int andOr(string);
//function to determine whether word given is
and / or
//-------------------------------------------------
//
MAIN PROGRAM
//-------------------------------------------------
int main() {
//initialize arrays
for (int z = 0; z < ucount; z++) {
strncpy(URLs[z], "\0", strmax);
} //initialize the URLs array
for (int z = 0; z < numIssues; z++) {
strncpy(titles[z], "\0", strmax);
} //initialize titles array
for (int z = 0; z < numIssues; z++) {
chk[z] = 0;
}
//initialize numIssues array
for (int z = 0; z < strmin; z++) {
strncpy(search[z], "\0", strmax);
} //initialize search array
//loop to get input - this part of program copied from site above
//Part 1
char * endptr;
//note to self:
// int i;
//is and the a and b chars really necessary?
double contentlength;
char buff[10000] = "\0";
//char a,b;
//#ifndef DEBUG
//only use these if it is a "real" run
const char * len1 = getenv("CONTENT_LENGTH");
contentlength = strtol(len1, & endptr, 10);
fread(buff, contentlength, 1, stdin);
//#ifndef
//Part 2
int x;
int y;
char hexstr[100] = "\0";
char buff2[10000] = "\0";
//loop to eliminate make sure user does not mess up input
for (x = 0, y = 0; x < strlen(buff); x++, y++)
{
switch (buff[x]) {
/* Convert all + chars to space chars */
case '+':
buff2[y] = ' ';
break;
/* Convert all %xy hex codes into ASCII chars */
case '%':
/* Copy the two bytes following the % */
strncpy(hexstr, & buff[x + 1], 2);
/* Skip over the hex */
x = x + 2;
/* Convert the hex to ASCII */
/* Prevent user from altering URL delimiter sequence */
if (((strcmp(hexstr, "26") == 0)) || ((strcmp(hexstr, "3D") == 0))) {
buff2[y] = '%';
y++;
strcpy(buff2, hexstr);
y = y + 2;
break;
}
buff2[y] = (char) strtol(hexstr, NULL, 16);
break;
/* Make an exact copy of anything else */
default:
buff2[y] = buff[x];
break;
}
} //end for loop - now buff2 has the content length string in it without
//any hex.
//bigstring buff3 = "search=\"learning and alphasmart\" OR
Dell & issues = all & sub = Search!";
bigstring buff3 = "search=\"Amy Anne DISDIER\" OR
Anne & issues = these & 2000 = on & sub = Search!";
//above for debugging only
parse(buff2);
//call the parse routine to extract information
/////////////////////////////
#ifdef DEBUG
cout << "got here!\n";
cout.flush();
#endif
/////////////////////////////
searchOut();
//begin output and make call to generate strings
//FOR DEBUGGING PURPOSES TO MAKE SURE THE SOURCE TABLE IS LOADING
/////////////////////////////
#ifdef DEBUG
cout << "\n\t\tSource truth table:\n\n";
for (x = 0; x < strmin; x++) {
cout << srcTruthTable[x] << " ";
if ((x % 5) == 0) {
cout << "\n";
}
} //end for
cout << "\n*****************************************\n\n";
#endif
/////////////////////////////
/******OUTPUT TO CLIENT BROWSER PART******/
cout << "Content-type: text/html\n\n" << "<HTML>\n<HEAD><TITLE>Your Search
Results! < /TITLE>" <<
"</HEAD>\n<BODY BGCOLOR=\"#FEFEC8\">\n<H2>The following articles were
returned: < /H2>\n<BR>\n<UL>";
x = 0;
//reinitialize
//all-purpose counter
while ((x < ucount) && (strcmp(URLs[x], "\0"))) {
//if URLs = 0 then equal
cout << "<LI><A HREF=\"" << URLs[x] << "\">" << titles[x] << "</A></LI>\n";
x++;
//increment x
} //end while
cout << "\n<BR>\n<BR><FONT COLOR=\"#FF0000\"><H3><B>" << numFound << " <
/B></FONT > article(s) found.\n < BR > \n < /H3>\n" <<
"<H4>Choose one of the links above or:</H4>\n" <<
"<FORM>\n<input type=\"button\" value=\"Search Again\"
onclick = " <<
"\"window.location=\'http://www.tcnj.edu/~technj/2000/newsrch.ht
ml '\">\n" <<
"<input type=\"button\" value=\"Back to home\" onclick=" <<
"\"window.location=\'http://www.tcnj.edu/~technj\'\">\n" <<
"</FORM>\n</BODY>\n</HTML>";
cout << "\n\n";
/////////////////////////////
#ifdef DEBUG2
cout << "\n\t\tTarget truth table:\n\n";
for (x = 0; x < strmin; x++) {
cout << trgTruthTable[x] << " ";
if ((x % 5) == 0) {
cout << "\n";
}
} //end for
cout << "\n*****************************************\n\n";
#endif
/////////////////////////////
cout.flush();
return 0;
} //end main
//------------------------------------------------------------------------------
//
PARSE FUNCTION
//------------------------------------------------------------------------------
void parse(bigstring argument) {
int c = 7;
//counter variable - initialize to
int d = 0;
//another counter variable
int quoteOn = 0;
//determines whether a quoted word is currently
being read
string temp = "\0";
//temporary string to hold
int firstTime = 1;
//for a quoted expression - to end it
while (argument[c] != '&') {
/* for OR functionality*/
if (((quoteOn) && ((argument[c + 1] == ' ') || (argument[c + 1] == '&'))) &&
//beginning of next word
((argument[c] == '\"') || (argument[c] == '\''))) {
quoteOn = 0;
//turn quoting off
if (firstTime) {
firstTime = 0;
search[bs][++d] = '\0';
}
//dump everything else on this
/*NO CALL to andOr needed- coming out of a quote*/
c = c + 1;
//get past quote and space
//if quoted phrase - get out
} //end 1st if - TO TURN QUOTES OFF AND END A WORD
else if (((argument[c] == '\"') || (argument[c] == '\'')) &&
(!quoteOn)) {
quoteOn = 1;
c++;
//get past the quote and continue
} //end 2nd else-if - TO TURN QUOTES ON
else if (argument[c] == ' ') {
//store character and increment both vars
if (!quoteOn) {
//only create a new word if this is not a
//quoted phrase
search[bs][++d] = '\0';
//dump everything else on this
/////////////////////////////
#ifdef DEBUG
cout << "\nPresend: " << search[bs] << "\nlENGTH = " << d;
#endif
/////////////////////////////
if (d < 5) { //declared a variable here so call happens once - \0
counts d will be 4
int call = andOr(search[bs]);
//call to andOR search
if (call == 2) {
//dictates when search is an and
//set truth table
search[bs][0] = '\0';
//first set location in string to null to dump
//set preceding word to beand connected by and
srcTruthTable[bs - 1] = 1;
srcTruthTable[bs] = 1;
//and next word to come followed by and
bs--;
//decrement to undo upcoming increment
//If user wishes to search for word and or OR, these must be
placed in quotes
}
if (call == 1) //it is an or - will be tossed
{
search[bs][0] = '\0';
//get rid of whatever was being read
bs--;
//and decrement to undo increment
}
}
/*Insert procedure this is not an empty string*/
d = 0;
//reinitialize d
bs++;
//next word
c++;
//get past space
} else {
//the quotes are on
search[bs][d++] = argument[c++];
//INSERT CHARACTER AND MOVE ON
}
//either way
} //end 3rd else if - TO END A WORD NORMALLY
else {
search[bs][d++] = argument[c++];
}
//only insert next character
} //end while
/*This Code block for OR functionality*/
search[bs][++d] = '\0';
//dump everything else on search
//now SEARCH has the word stored within it - get next variable issues
//for debugging purposes
/////////////////////////////
#ifdef DEBUG
cout << "\n\n\nBegin here...\n";
for (int i = 0; i <= bs; i++) {
cout << search[i] << "\n";
cout << "Bigstring: " << i << "\n";
}
cout << "\n\n";
#endif
/////////////////////////////
/*CODE FROM HERE ON THROUGH REMAINDER OF METHOD DEALS WITH
CHECKBOXES AND OTHER STUFF - NOT THE SEARCH TERMS! */
while (argument[c] != '=') {
c++;
}
c++;
//get past equal sign
radissues = argument[c];
//radissues is a character - no need for null
//type of search determined - all issues
if (radissues == 't') { //issues encountered - more parsing
//else everything is already nulll
do {
d = 0;
//reinitialize d
strncpy(temp, "\0", 5);
while (argument[c] != '&') {
c++;
}
//get to next variable
c++;
//throw away amperstand
while (argument[c] != '=') {
temp[d++] = argument[c++];
}
temp[++d] = '\0'; //dump everything else on temp
if (strcmp(temp, "w96") == 0) chk[0] = 1;
if (strcmp(temp, "s96") == 0) chk[1] = 1;
if (strcmp(temp, "f96") == 0) chk[2] = 1;
if (strcmp(temp, "s97") == 0) chk[3] = 1;
if (strcmp(temp, "w98") == 0) chk[4] = 1;
if (strcmp(temp, "f98") == 0) chk[5] = 1;
if (strcmp(temp, "2000") == 0) chk[6] = 1;
} while (strcmp(temp, "sub"));
} //end if
//do while this is not equal to sub
else {
for (int x = 0; x < numIssues; x++) {
chk[x] = 1;
}
//check the whole article
} //end else
} //end of parse function - array chk set
//------------------------------------------------------------------------------
//
SEARCHOUT FUNCTION
//------------------------------------------------------------------------------
void searchOut() {
int count = 0;
int c = 0;
//big counter
//small (inner loop counter)
for (count = (numIssues - 1); count >= 0; count--) {
if ((chk[count] == 1) && (count == (numIssues - 1))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../2000/";
bigstring address = "http://www.tcnj.edu/~technj/2000/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} //end 1st if
if ((chk[count] == 1) && (count == (numIssues - 2))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../Fall98/";
bigstring address = "http://www.tcnj.edu/~technj/Fall98/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} //end 2nd if
if ((chk[count] == 1) && (count == (numIssues - 3))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../win98/";
bigstring address = "http://www.tcnj.edu/~technj/win98/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} // end 3rd if
if ((chk[count] == 1) && (count == (numIssues - 4))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../spr97/";
bigstring address = "http://www.tcnj.edu/~technj/spr97/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} //end 4th if
if ((chk[count] == 1) && (count == (numIssues - 5))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../fall96/";
bigstring address = "http://www.tcnj.edu/~technj/fall96/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} //end 5th if
if ((chk[count] == 1) && (count == (numIssues - 6))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../sprsum96/";
bigstring address = "http://www.tcnj.edu/~technj/sprsum96/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} //end 6th if
if ((chk[count] == 1) && (count == (numIssues - 7))) {
for (c = 0; c < maxfiles; c++) {
if (strcmp(location[count][c], "\0")) {
string fileLoc = "../../win96/";
bigstring address = "http://www.tcnj.edu/~technj/win96/";
strcat(fileLoc, location[count][c]);
strcat(address, location[count][c]);
checkFile(fileLoc, address);
//call function to chk file
}
} //end for
} //end 7th if
} //end BIG FOR
} //END FUNCTION SEARCHOUT
//------------------------------------------------------------------------------
//
CHECKFILE FUNCTION
//------------------------------------------------------------------------------
void checkFile(string filespec, bigstring adr) {
int done = 0;
//to determine if word has been found
string sample = "\0";
//to hold the word being tested
bigstring line = "\0";
//to hold the current line
int lineLength = 0;
//length of the line of characters being read
int pcount = 0;
//parsing counter
int scount = 0;
//sample counter
int searchLength[strmin];
//lengths of the search variables stored in
//corresponding
//positions in this array
int gotTitle = 0;
int titleRead = 0;
int titleCount = 0;
int URLFlag = 0; //title truth variable
//indicates that the title is now being read
//title string counter
//flag to test whether a valid URL has been
//gathered from a file
ifstream fin; //input file stream
//for loop here - collect and store lower and upper case characters of all
search terms;
//then store the lengths of all the search strings
for (int i = 0; i <= bs; i++) {
firstChar[i] = (char) tolower(search[i][0]);
capFirstChar[i] = (char) toupper(search[i][0]);
searchLength[i] = strlen(search[i]);
}
fin.open(filespec);
//open the file
if (!fin) {
cout << "Content-type: text/html\n\n" << "Could not open" << filespec;
exit(0);
}
//NOW THE FILE IS OPEN AND GOOD
done = 0;
//reinitialze done to false
//************************INITIALIZE TRUTH TABLE*********************
int trgTruthTable[strmin] = {
0
};
//FOR THIS FILE/////////////
int oldpcount = 0;
//need should an and be encountered
//in the file
while (fin && !done) {
//while the end of file has not been encountered...
/////////////////////////////////////////////////////////////////////
fin.getline(line, strmax); //read either 500 (strmax) characters or up to
//EOL
lineLength = strlen(line); //store the length of the line
for (pcount = 0; pcount < lineLength; pcount++) {
/*****************************FOR GETTING TITLE*************************/
if ((line[pcount] == '<') && (!gotTitle)) {
int maxRead = 0;
strncpy(sample, "\0", strmin);
//reinitialize sample
scount = 0;
//and the counter
pcount++;
//get past the <
while (line[pcount] != '>' && (maxRead < 6)) {
sample[scount] = line[pcount];
//space to get out
scount++;
//increment sample counter
pcount++;
//otherwise - increment only pcount
if (pcount > lineLength) {
break;
}
//protection against core dump
maxRead++;
//maximum it should read
} //end while
scount++;
sample[scount] = '\0';
//dump the rest of characters in sample
if ((compareThem(sample, "title")) == 0) {
titleRead = 1;
gotTitle = 1;
//title read is now set for loop below
}
pcount++;
} //END 1st if
//must increment to get past the >
/*****************************FOR READING TITLE*************************/
if ((line[pcount] != '<') && titleRead) {
//is title being read - if yes
//store char for it
if (((int) line[pcount]) > 31) {
//cut out weird chars
titles[atUcount][titleCount] = line[pcount];
titleCount++;
} //increment titleCounter
//pcount is incremented in BIG for loop - no need to increment here
} //END 2nd if
/*****************************FOR STOPPING TITLE*************************/
if ((line[pcount] == '<') && titleRead) {
pcount++;
//get past the <
if (line[pcount] == '/') {
//test to see if it is an end tag
int maxRead = 0;
strncpy(sample, "\0", strmin);
//reinitialize sample
scount = 0; //and the counter
pcount++; //get past the / - yes it is?
while ((line[pcount] != '>') && (maxRead < 6)) {
sample[scount] = line[pcount];
//space to get out
scount++;
//increment sample counter
pcount++;
//otherwise - increment only pcount
if (pcount > lineLength) {
break;
}
//protection
maxRead++; //maximum it should read
//AGAINST BLOODY CORE DUMP!
} //end while
scount++;
sample[scount] = '\0';
//NOW dump the rest of characters in sample
if ((compareThem(sample, "title")) == 0) {
gotTitle = 1;
titleRead = 0;
}
//title has been obtained - no longer reading
pcount++;
//must increment to get past the >
}
/////////////////////////////
#ifdef DEBUG
cout << "\nTitle obtained: " << filespec << "\n";
cout.flush();
#endif
/////////////////////////////
} //END 3rd if
/******************************FOR SAMPLE*******************************/
if (!titleRead && gotTitle && (!isalnum(line[pcount - 1]))) {
for (int i = 0; i <= bs; i++) {
//label for and
oldpcount = pcount;
//need should an and be encountered
if ((line[pcount] == firstChar[i]) || (line[pcount] ==
capFirstChar[i])) {
/////////////////////////////
#ifdef DEBUG
cout << "\nOld Pcount in loop" << oldpcount << "\n";
#endif
/////////////////////////////
//if a match, look for chars
strncpy(sample, "\0", strmin);
//reinitialize sample
scount = 0; //and the counter
while (strlen(sample) != searchLength[i]) {
sample[scount] = line[pcount];
pcount++;
scount++;
if (pcount > lineLength) {
break;
}
//protection
//AGAINST BLOODY CORE DUMP!
} //end while
//increment both counters
scount++;
sample[scount] = '\0';
//dump the rest of characters in sample
/*FINISH*/
//test to see if word in sample matches the search word
/////////////////////////////
#ifdef DEBUG
cout << "looking up: " << sample << " comparing to " << search[i] << " bs=" <<
bs << "\n";
#endif
/////////////////////////////
int compSrch = compareThem(sample, search[i]);
/////////////////////////////
#ifdef DEBUG
cout << "\ncompSrch (Before truth tables): " << compSrch << "\n";
#endif
/////////////////////////////
if (compSrch == 0) {
//got it!
if (srcTruthTable[i] == 0) {
/////////////////////////////
#ifdef DEBUG
cout << "Supposedly storing " << adr << "\n";
#endif
/////////////////////////////
done = 1;
//got a word from the file - get out
i = bs + 1;
//get out of inner loop
pcount = lineLength;
//got a word - get out of outer loop
strncpy(URLs[atUcount], adr, strmax);
//store results in ucount (array - for now)
URLFlag = 1;
atUcount++;
numFound++;
//increment all necessary vars
gotTitle = 0;
//valid URL flag - increment URL counter
} else {
//ANDS
trgTruthTable[i] = 1;
int srcStart = 0;
//location where this group of "ands begins"
int srcEnd = 0;
//location where this group of "ands ends"
int iA = i;
//1st location counter
int iB = i;
//2nd location counter
int ok = 1;
//assumes that this will be the last of the ands
//Problem
while (srcTruthTable[iA] == 1) {
if (iA > 0) {
//cannot go past the first element of the string
iA--;
} else {
break;
}
//get out i must be 0
} //end while
(iA != 0) ? srcStart = iA + 1: srcStart = 0;
//location of beginning of ands stored
while (srcTruthTable[iB] == 1) {
if (iB <= (strmin)) {
iB++;
} else {
break;
}
//last position in truth table - get out
} //end while
srcEnd = iB - 1;
/////////////////////////////
#ifdef DEBUG
cout << "\nstart" << srcStart << "\nend" << srcEnd << "\n";
#endif
/////////////////////////////
for (int iC = srcStart; iC <= srcEnd; iC++) {
/////////////////////////////
#ifdef DEBUG
cout << "\ntrgtruth " << iC << " is " << trgTruthTable[iC] << "\n";
#endif
/////////////////////////////
if (trgTruthTable[iC] == 0) {
//if this equals 0 and not entirely fulfilled
ok = 0;
iC = srcEnd + 1;
//this is not yet ready to qualify as a file
} //set not ok and break out of for loop
} //end for loop
if (ok) {
//repeat above if all conditions passed - else
//forget it!
done = 1;
//got a word from the file - get out
i = bs + 1;
//get out of inner loop
pcount = lineLength;
//got a word - get out of outer loop
strncpy(URLs[atUcount], adr, strmax);
//store results in ucount (array - for now)
URLFlag = 1;
atUcount++;
numFound++;
//increment all necessary vars
gotTitle = 0;
//valid URL flag - increment URL counter
} //end ifok conditionO
} //end else
} //end if compSrch == 0
/////////////////////////////
#ifdef DEBUG
cout << "\ncompSrch " << compSrch << "\n";
#endif
/////////////////////////////
//THEY DID NOT COMPARE CORRECTLY - SEE IF THIS IS AN AND (or OR) with the
same
letter
if (compSrch != 0)
{
pcount = oldpcount;
}
//restore the parsing counter to the beginning
//of the word to be checked
} //end for
}
//end Inner for loop for testing each search
//term
} //END 4TH OUTER IF
} //end for
} //end while
/****************(Cleanup)****FOR VALIDATING TITLE********************/
if (!URLFlag) {
//if the URL flag is not set - dump the tile
//no need to set ucount - it was never
//incremented if true
strncpy(titles[atUcount], "\0", strmax);
//reinitialize the array and counter
titleCount = 0;
//pcount is incremented in BIG for loop - no need to increment here
} //END 5th if
fin.close();
//close the file
} //end (auxillary) function checkfile
//------------------------------------------------------------------------------
//
AUXILLARY COMPARETHEM FUNCTION
//------------------------------------------------------------------------------
int compareThem(string a, string b) {
int lengthA = strlen(a);
int lengthB = strlen(b);
int comp = 0;
//comparison counter
int tmp1, tmp2;
//2 temporary integers
if (lengthA != lengthB) {
return 1;
}
//nope - already know these are not =
for (comp = 0; comp < lengthA; comp++) {
tmp1 = tolower(a[comp]);
tmp2 = tolower(b[comp]);
if (tmp1 != tmp2) {
return 1;
}
//not equal
} //end for
return 0;
//all compared ok - must be equal
} //end auxillary functionc compareThem
//------------------------------------------------------------------------------
//
AUXILLARY ANDOR FUNCTION
//returns 0 if neither
//returns 1 if OR
//returns 2 if AND
//------------------------------------------------------------------------------
int andOr(string AO) {
string tester = "\0";
int length = strlen(AO);
//get the string length of the argument
for (int loop = 0; loop < length; loop++) {
tester[loop] = tolower(AO[loop]);
}
//now test it
/////////////////////////////
#ifdef DEBUG
cout << "\nIn AndOR: AO = " << AO << "\ntester = " << tester << "\n";
#endif
/////////////////////////////
if ((strcmp(tester, "or")) == 0) {
return 1;
} else if ((strcmp(tester, "and")) == 0) {
return 2;
} else return 0;
} //end auxiliary ANDOR function
The Search Routine
In order to conduct the development of the "workhorse" of the
search engine, I
opted to divide the code into two major parts or functions: one
function, parse(string)
which separates the information of the given in the CGI environment
variables and another function searchOut(),
which performs the manipulation of strings and file operations on all
of the selected documents on the site
using another function, checkfile().
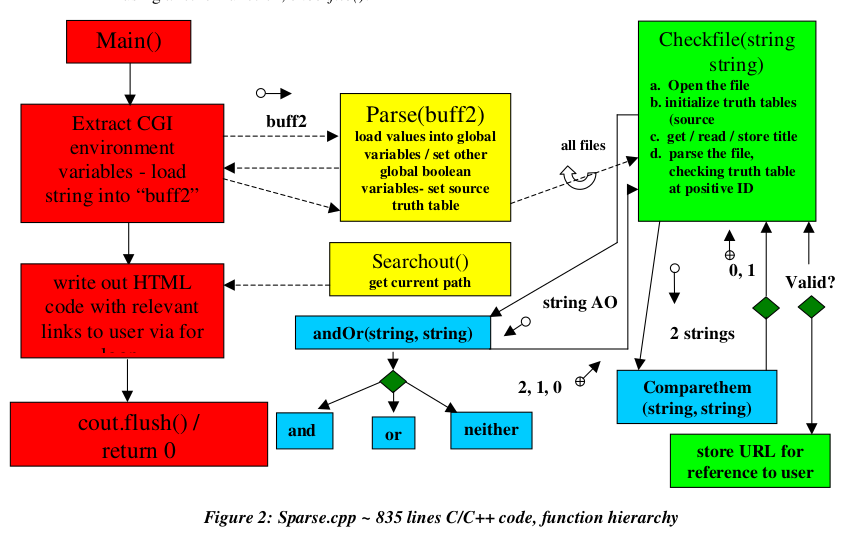
The program‘s hierarchy of these functions along with two auxiliary
functions,
andOr(string, string), for supporting and / or operations, and
comparethem(string, string),
for determining the equality of any two string expressions is
indicated in the flowchart
shown in figure 2. This program, denoted, "sparse.cpp," acts as
the complete backend
responsible for dynamically returning HTML search results to the
user. One might notice
that the program is relatively large in comparison to typical C/C++
classes designed by
students and that the program‘s functionality might be better
defined if the the large
sparse program was broken down into several different C/C++ classes.
A more object-
oriented approach was in fact attempted in the course of developing
this system, but due
to extensive problems with CGI interfacing in the program caused by
compiler and
system upgrades (unbeknownst to the me as the programmer at the
moment they were
performed), enough time to complete such an approach was not
available.
The Search Routine Code Examined
In a nutshell, the program‘s parse and search functions are as
follows::
a. The parse function obtains its string, denoted argument as the
main function passes
buff2 to it.
b. The parse function gathers each possible search term from this
string (or phrases
enclosed in quotes counting as a single search term), and stores
them in an array of search
terms search. Ands and Ors are eliminated from the search string as
the program sets a
global array of 0s and 1s denoted the sourcetruthtable. Taken
verbatim from the
program‘s documentation, the sourcetruthtable works in tandem with
the
targetruthtable, another global array of 0s and 1s, to facilitate
and/or match
expressions as follows:
[The] truth tables indicate "and" and "or" values in search
string. If
a word is encountered that is part of an and statement, that location
in the
corresponding truth table will be set to a 1. When a value is
checked, a
check will be made to determine whether the corresponding entry in
the
truth table and the next consecutive one are both 1. If they are, an
and
value has been encountered, and another word must be obtained in
order
for the search to return a yes. When all consecutive ones [in a
particular
location] are matched and [a group of 1s] in the target truth table
matches
the location and number of 1s in the source truth table, the search
criteria
returns a yes.
In this scheme, the source truth table, sets as the environment
variable for the search
string is parsed and each search term or phrase is added to
successive places in the array
search. As of the time of this writing, the search engine can analyze
a maximum of 40
different search terms of phrases (delimited by single or double
quotes) or any
combination thereof, not counting the And or Or words separating
these phrases. This
number is based on a static (constant) integer expression in the
program, strmin and could
be increased to accommodate larger numbers of terms, but this was believed
to be sufficient at the time of this writing. As already mentioned,
the auxiliary function,
andOr(string) contains the subroutine that actually determines
whether a specific word is
AND, OR, or neither of these values and returns a status integer
indicating the result. It
should be noted that the search engine, in addition to being full
text and supporting up to
40 possible search terms, and supporting user selection of which
documents to retrieve,
supports the ability to search for entire quoted phrases of words in
addition to singletons.
The phrases must be placed between corresponding single or double
quotes for this
function to operate.
c. After the source truth table has been set and all search words
have been loaded into the
search array, the parse function moves on to set the global
variables associated with
the issues to be searched. Like the truth tables, these variables
use a Boolean binary
system to establish whether certain issues should be searched. Each
issue has a
variable associated with it. If that variable is set to one, the
issue will be searched in
the call to searchOut(); otherwise the issue will be skipped.
Furthermore, whether or
not the radio button associated with the selection of issues is set
determines whether
the checkbox variables from the form will be assessed at all. If the
value of the radio
button is "all," all of the Boolean binary variables associated
with the individual issues
will be checked.; this is the default setting. If it is "these,"
only issues whose
checkboxes have been set on the form will be checked. All of the
variable setting
occurs on the search engine‘s HTML form.
d. Now that the global variables have been set, the program returns
to main() where the
searchOut() function is called. Upon entry into this function, each
of the global
variables containing the Boolean binary value determining whether a
specific issue is
to be searched is evaluated, starting with the most current issue.
If searchOut()
determines an issue is to be evaluated and the number of articles in
a certain issue has
not been exceeded (i.e. the a file is not equal to an empty string),
the string variable
fileLoc is set to the relative path to the directory containing the
issue, the address
variable is set to the URL that contains the issue should it need to
be returned as valid
later, and the checkfile(string, string) function is called to check
that file. This process
is repeated in searchOut() for every valid file (not "\0" empty
string) in every valid
issue to be searched.
e. Upon the calling of the checkfile(string, string) function, the
system issues a call to
open the file to be parsed and proceeds to parse the file line by
line until either the
search criteria have been satisfied to return the file as containing
the search item(s) or
the end of the file has been reached. (Of course, safe guards are
present to stop the
program should a invalid file handle be called). Before the search
can begin, however,
the checkfile(string, string) function must initialize variables
necessary to its operation.
These include:
• the target truth table to all 0s - once the inner loop is entered
and a group of ones
makes their way into the target truth table surrounded by 0s having
matching
locations in the source truth table, the search can return a true
result.
• the corresponding letter to the first character of the search
term in both cases
(should it be a letter) and the length of the search term so that
each time that character
arises in the text, a possible match can be evaluated. This
information is stored for
each search term i (where i is 0 to 39) in the arrays firstChar[i],
capFirstChar[i]
(capitalized first character), and searchLenth[i] respectively.
• variables for storing information regarding whether the title has
been obtained for
the document. The search cannot begin searching for sample words
until the title of
the document has been gotten. The title associated with the URL path
to be
returned to the user upon a successful search is based upon the title
of the HTML
document which appears between the <title> </title> HTML
tags. No search is
returned as valid for a document if the sample search term only
resides between these
two tags (as the engine does not actually begin searching for a match
until the title has
been obtained- thus the title must appear at the beginning of every
HTML document-
as is appropriate - in the header). This creates the restriction that
every document
must have a title, even if it is only one character for this search
engine to operate
properly. This is necessary to return something more descriptive as a
link should the
document be returned to the user as a match other than a URL path.
This should not
cause a problem in the future as good HTML coding practice REQUIRES a
title field
to be present within the header field of an HTML document. All
principle
information stored regarding the title is found in the variables
gotTitle (a binary
Boolean variable to determine whether the title has been obtained),
titleRead (a binary
Boolean variable to determine whether the title is currently being
read), and titleCount, a
counter for the this process of getting the title.
• a value determining whether the search is ready to terminate and
return, done, a
binary Boolean variable originally initialized to 0, and a binary
Boolean value
corresponding to whether the URL for this file should be stored; this
only gets set to 1
later should the document return true to the query.
The checkfile(string, string) function uses the auxiliary function
compareThem(string
string) as already noted to compare a sample value against a search
term.
f. Once searchOut() has called checkfile(string, string) for every
valid file, that is not an
"\0" empty string file in every issue, the program returns
control back to the main()
function where a few simple cout functions combined with a for loop
write out HTML
results to the user. At the conclusion of this process, a
cout.flush() is called to
complete the process and the program terminates normally, returning
0.